
随着深度学习模型的出现和应用场景的扩大,对大量高质量数据的需求也越来越大。然而,真实世界的数据往往是有限的,特别是对于特定任务或特定领域的数据而言。为了解决数据稀缺问题以及扩大数据集的规模和多样性,微美全息(NASDAQ:WIMI)提出了用于卷积神经网络的数据增强技术。
数据增强是一种在训练神经网络时使用的技术,旨在通过对原始数据进行变换和扩充,生成更多的训练样本,其可以帮助解决数据不足的问题,并提高网络模型的泛化能力。
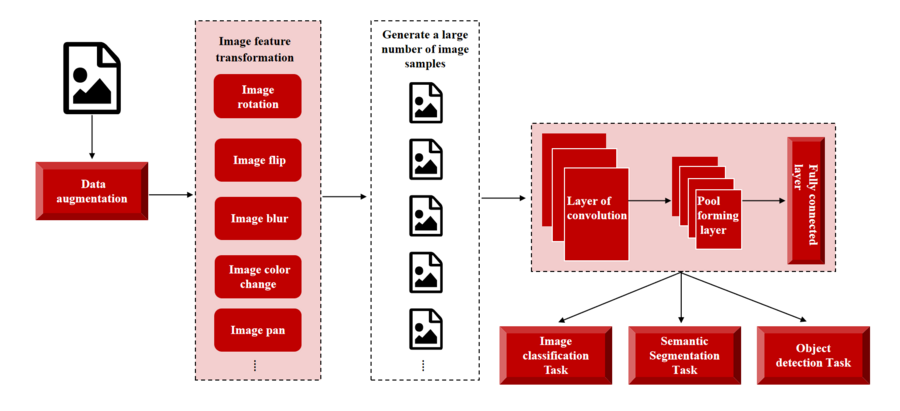
数据增强的目的是通过对原始数据进行一系列变换,生成新的训练样本,以增加数据集的多样性,这样可以使网络模型更好地学习到数据的特征,并提高其泛化能力。数据增强的方法可以包括图像的旋转、翻转、缩放、平移等操作,以及对图像进行添加噪声、模糊化、颜色变换等处理,通过这些变换,增加数据的多样性和复杂性,从而使模型更好地适应不同的环境和条件,提高模型的鲁棒性,例如,在图像分类任务中,可以通过对图像进行随机旋转、平移和缩放,生成不同角度、位置和尺度的图像样本。这样可以使模型更好地学习到物体的不同姿态和尺度变化,从而提高其对新图像的分类准确率。
在卷积神经网络中,数据增强可以应用于图像分类、目标检测、语义分割等任务。例如,在图像分类任务中,通过对原始图像进行一系列的变换和处理,生成新的训练样本,增加数据样本的多样性,使得模型可更好地适应不同的图像变化,更准确得完成图像分类的任务。在目标检测任务中,数据增强也起到了重要的作用。目标检测任务旨在在给定图像中定位和分类多个目标,为了提高模型的性能和泛化能力,数据增强技术可以用于扩充训练集,增加样本的多样性和数量。在语义分割任务中,数据增强同样也扮演着重要的角色。语义分割是指将图像中的每个像素都标注为属于某个类别的任务,因此需要大量的标注数据来训练模型。然而,获取大规模的标注数据是非常困难和耗时的。这时,数据增强技术可以通过对现有的标注数据进行一系列的变换和扩充,来增加训练数据的多样性,提高模型的泛化能力。
数据增强技术在卷积神经网络中具有许多优势,通过对原始数据进行旋转、翻转、缩放、平移等变换,可以生成更多具有差异性的样本,使模型更好地学习到数据的不同特征和变化模式,提高模型的泛化能力。同时,其可利用引入噪声和随机变换的方式来模拟真实世界中的不确定性,使模型对输入数据的变化更加稳健,增强模型鲁棒性,降低过拟合的风险。通过合理选择和应用数据增强技术,可以提高模型的性能和效果。
随着人工智能技术的不断发展,卷积神经网络数据增强也在不断演进和创新。传统的数据增强方法通常是基于一些预定义的变换操作,如旋转、平移、缩放等。然而,这些方法可能会引入一些不必要的噪声或信息丢失。未来WIMI微美全息将研究通过学习算法,将数据增强技术与模型的反馈机制相结合,实现自适应的数据增强,使网络可以根据输入数据的特征和任务需求,自动选择合适的数据增强方式,从而提高模型的性能和鲁棒性。另外,生成模型(如生成对抗网络)的发展也为数据增强提供了新的思路,其在数据增强中也有着广阔的应用前景。生成式对抗网络等模型可以学习数据的分布特征,从而生成更真实、多样的数据样本。未来WIMI微美全息也将研究将生成模型与数据增强技术结合,通过生成模型生成新的数据样本,并将其用于数据增强,有效解决数据稀缺的问题,进一步提升模型的泛化能力。随着多模态数据的广泛应用,跨模态数据增强成为一个重要的发展方向。未来可以研究如何通过数据增强技术进行跨模态数据的转换和扩充,以提高模型在跨模态任务上的性能。
数据增强技术在卷积神经网络中的未来发展前景非常广阔,未来WIMI微美全息将通过结合自适应、生成模型、和跨模态等方面的研究,进一步提高模型的泛化能力和性能,并扩大其应用范围。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
 比亚迪毛利率大涨,特斯拉怕
比亚迪毛利率大涨,特斯拉怕
 美军集束炸弹袭击幸存者:家
美军集束炸弹袭击幸存者:家
 铁路暑运累计发送旅客超6亿
铁路暑运累计发送旅客超6亿
 车险的这些改变 你感受到了
车险的这些改变 你感受到了
 半导体板块涨3.46% 利扬芯
半导体板块涨3.46% 利扬芯
 深圳前海综保区9月进出口创
深圳前海综保区9月进出口创
 深圳坪山新能源车产业园一期
深圳坪山新能源车产业园一期

 48小时点击排行
48小时点击排行


